CERBERUS 2080 is a modern 8-bit computer designed by Bernardo Kastrup. See more on the official page.. This computer can be built form off-the shelf parts that are currently available and all parts are through-hole, so they can be soldered by the average hobbyist. It contains two CPUs, a Z-80 and a 65C02, only one of which can run at any given time. The boot process and I/O are controlled by an ATMega328p microcontroller.
CERBERUS 2080 does have video circuitry. It implements a text mode with 30 rows of 40 characters each. There are 256 8x8 character bitmaps. Both the character bitmaps and the screen contents are implemented in dual port RAMs that are mapped to a 4kB section of the CPU address space. Text mode has two advantages over bitmapped mode:
Having redefinable character bitmaps offers additional flexibility over a character set in ROM. A few possibilities.
I don't own a real CERBERUS 2080 and I do not plan to purchase one soon. However, there is an emulator written by Paul Robson. I made a few modifications to it:
Even though BBC Basic on the Cerberus allows you to edit programs using the TAB key as the COPY key of the BBC Micro, this is not an ideal way to do editing. But because we run an emulator, we can use a text editor to do the editing. Any text editor? Not quite, because BBC Basic loads and saves its programs in tokenized form. Fortunately there is an other version of BBC Basic, BBC Basic for SDL2.0, also written by R.T. Russell. This version is available for Windows, Linux and Mac, it has an editor that can load and save both ASCII and BBC tokenized formats. This is the same tokenized format as used by the Z80 Basic on Cerberus.
This way I can edit a BBC Basic program in the SDL IDE, save it in the storage directory of the emulator and immediately LOAD it from Basic in the emulator. Of course I can also run it in BBC Basic for SDL. The Z80 version of BBC Basic is more limited than the SDL version. For example the block structured IF..ENDIF is not supported.
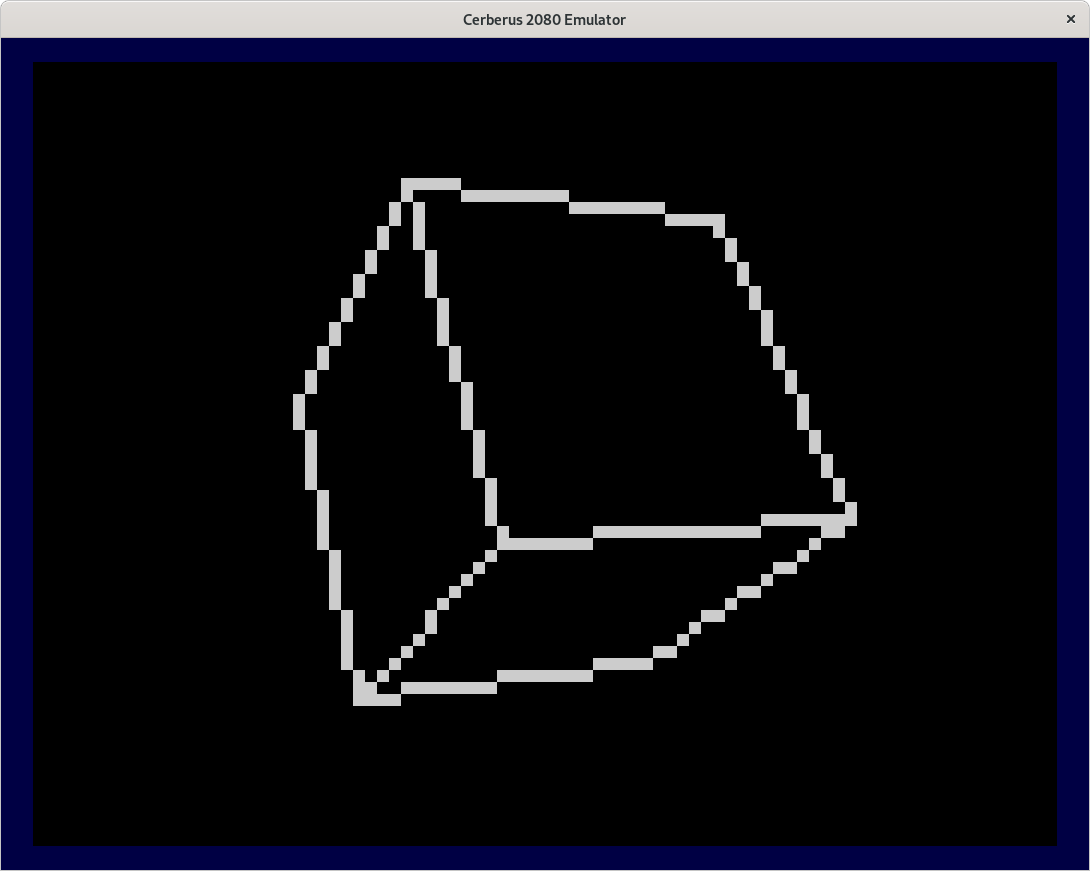
Dean Belfield's port of BBC Basic supports a limited set of plot and draw commands and they use the block graphics characters that are in the default character set. Each character cell is divided into 2x2 subblocks of 4 pixels wide and 4 pixels high. This way a screen of 80x60 pixels can be used. This is comparable to the graphics on the ZX-81 for example. This is an example of a rotating cube drawn with block graphics.
I wanted to check how practical it was to make line drawings at pixel resolution by dynamically redefining the character bitmaps. Techniques like this had been implemented in the 1980s on machines with redefinable character bitmaps, such as the TI-99/4A and the Jupiter Ace. It is impossible in principle to draw arbitrarily complex patters that fill the entire screen, simply because there are not enough bits in 256 character bitmaps to cover all 320x240 pixels. There are 1200 character positions on the screen and there can be only 256 distinct characters.
I first implemented and tested my program in BBC Basic for SDL. BBC Basic lets you redefine the character bitmaps in a portable way, using VDU 23. I used MODE4 to have a screen of 40 characters wide and 32 characters tall. This is almost the same as on CERBERUS.
So I set out to allocate two memory areas using the DIM command:
Both memory areas can be accessed using the '?' operator. Here comes the trick:
The original version used character codes 128..255 for graphics purposes. Character codes are allocated from 128 to 255. When I plot a pixel, I take the following steps:
This is the first program graph01 in tokenized form and in ASCII. Soon after this I created the second version of the program. It made the following changes:
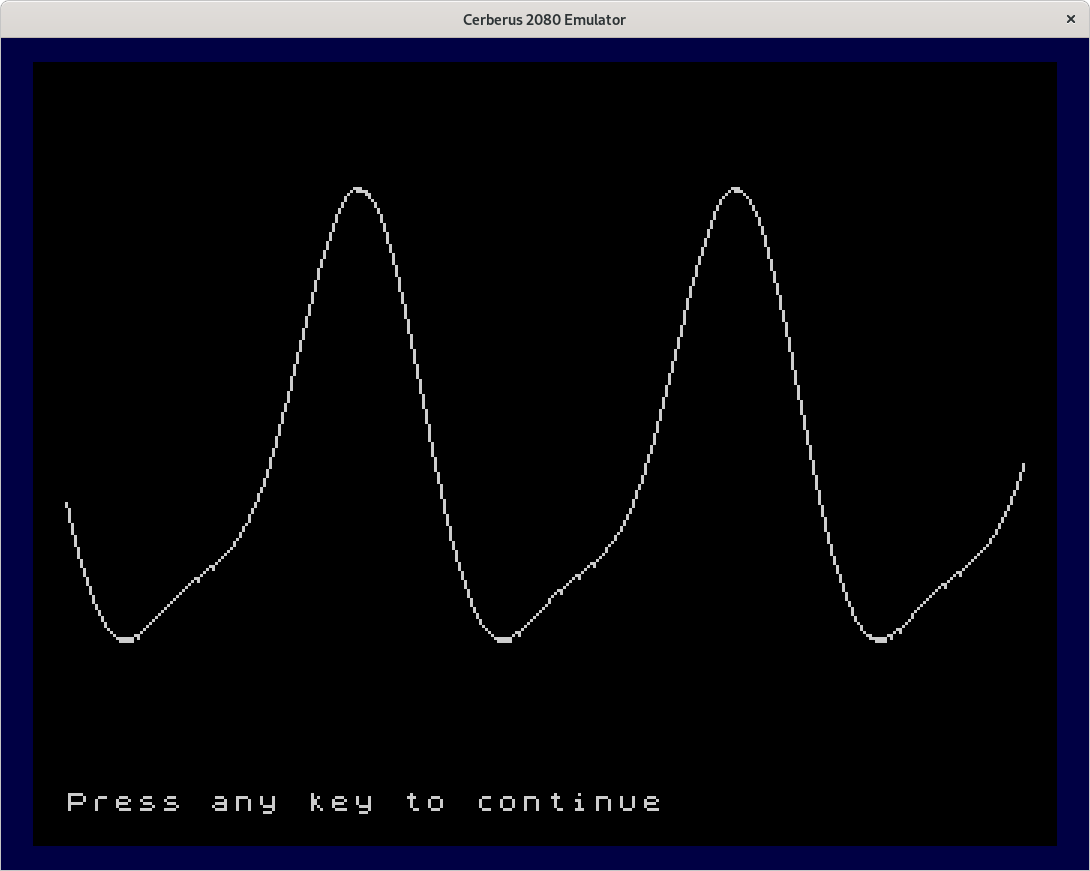
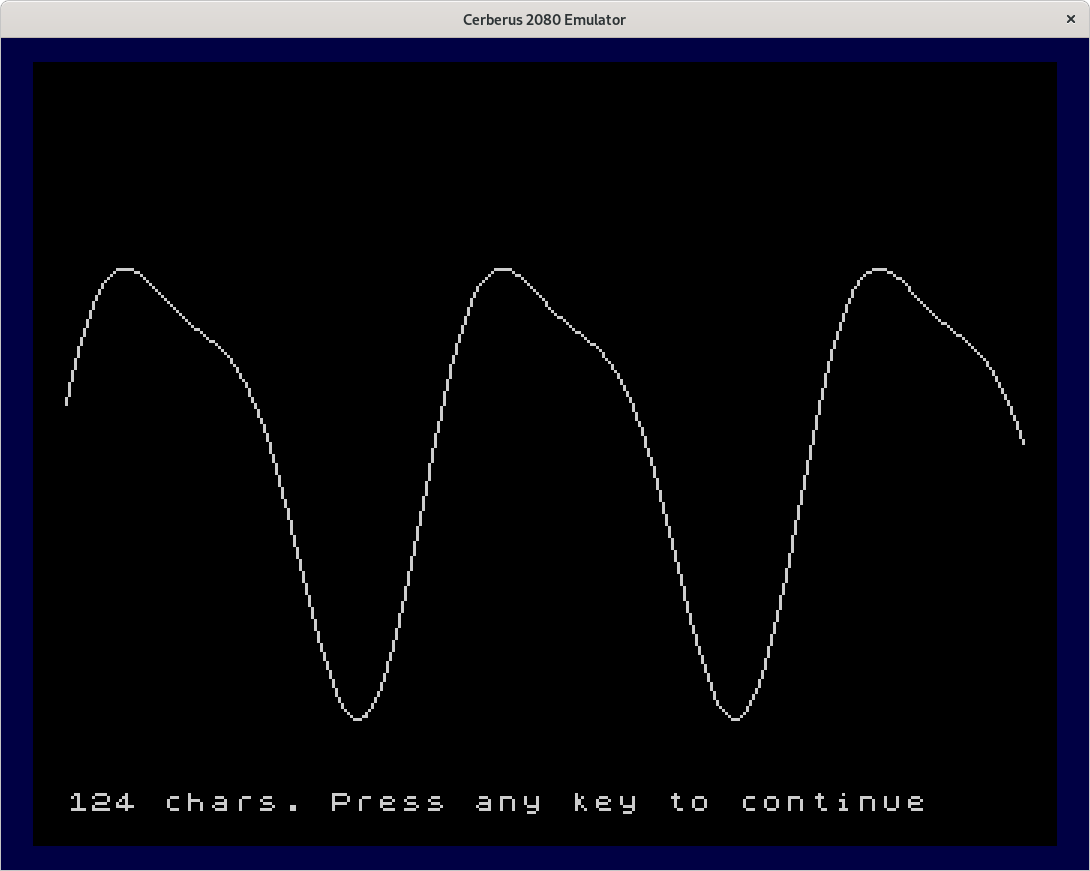
This is the second program graph02 in tokenized form and in ASCII. You can clearly see the difference between the graph of a sine with a second harmonic drawn by the first program and the same graph drawn by the second program. Apart from the Y reversal, the second graph is much smoother. Also the number of used characters is shown. This graph already uses 124 out of 128 character codes.
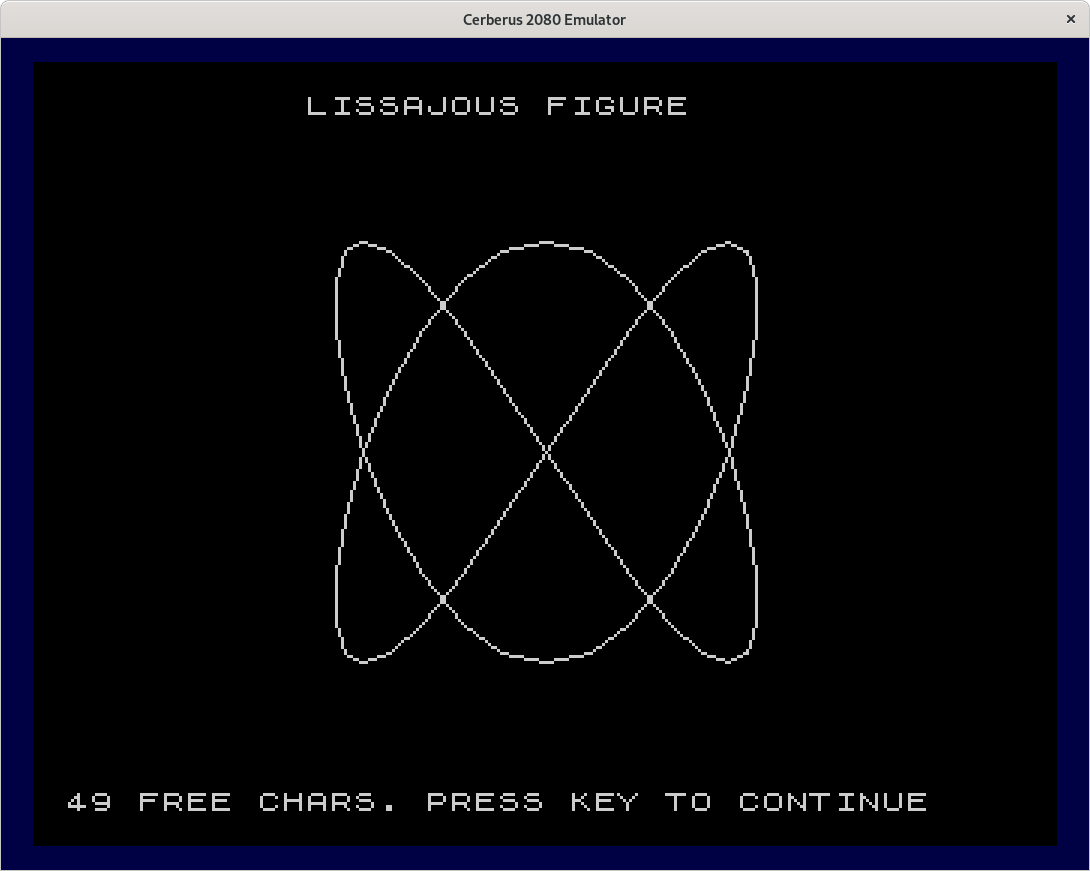
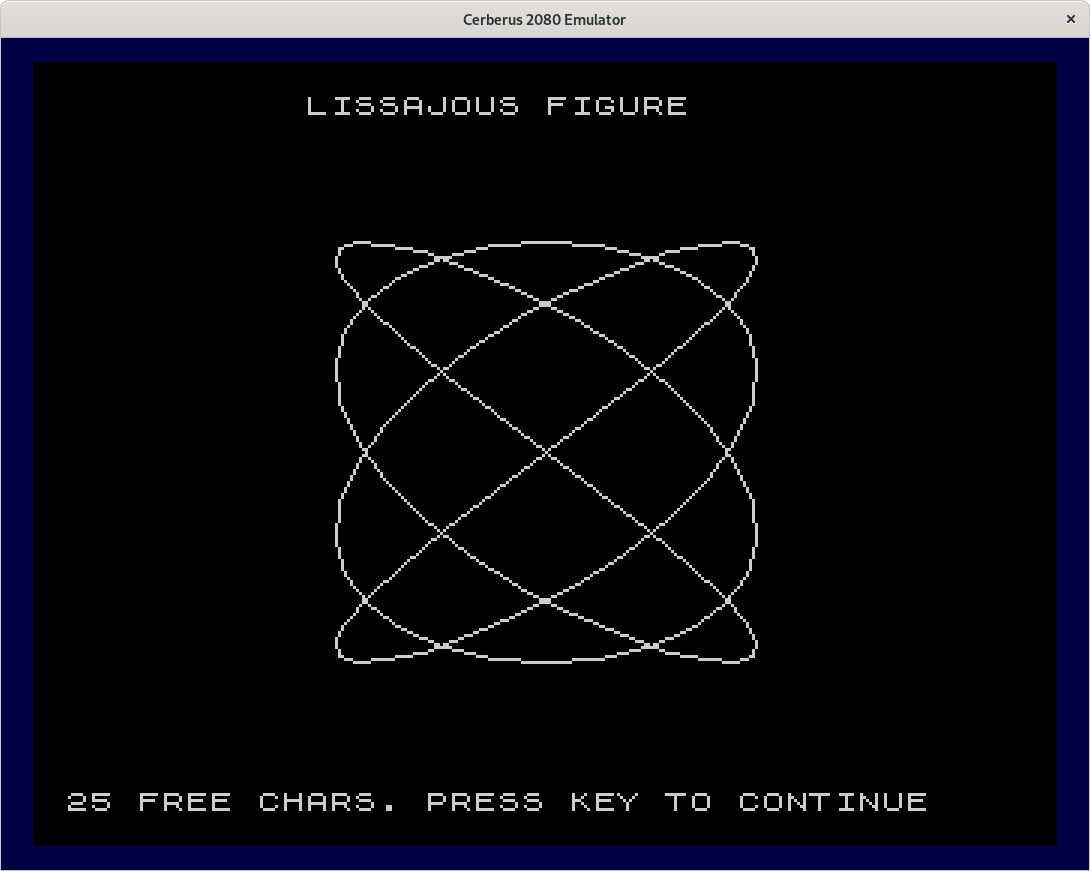
The second program showing a square and two triangles, and the Lissajous figure.
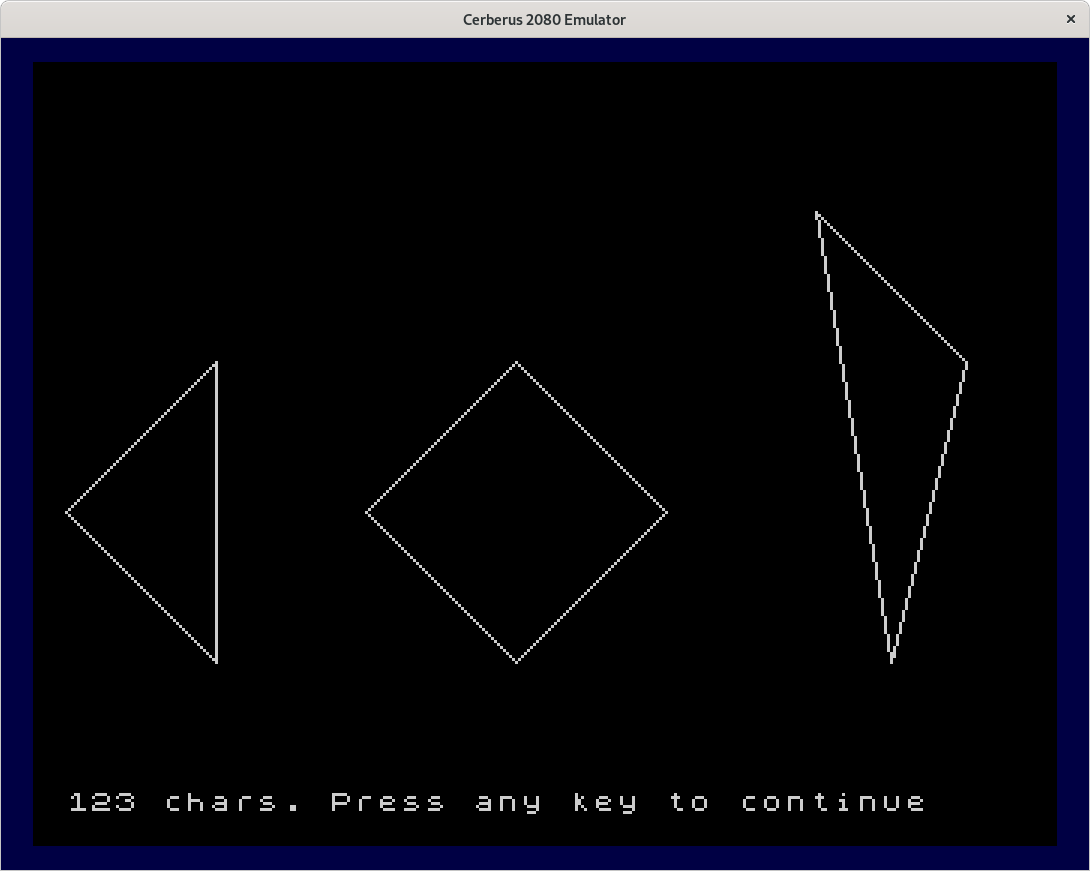
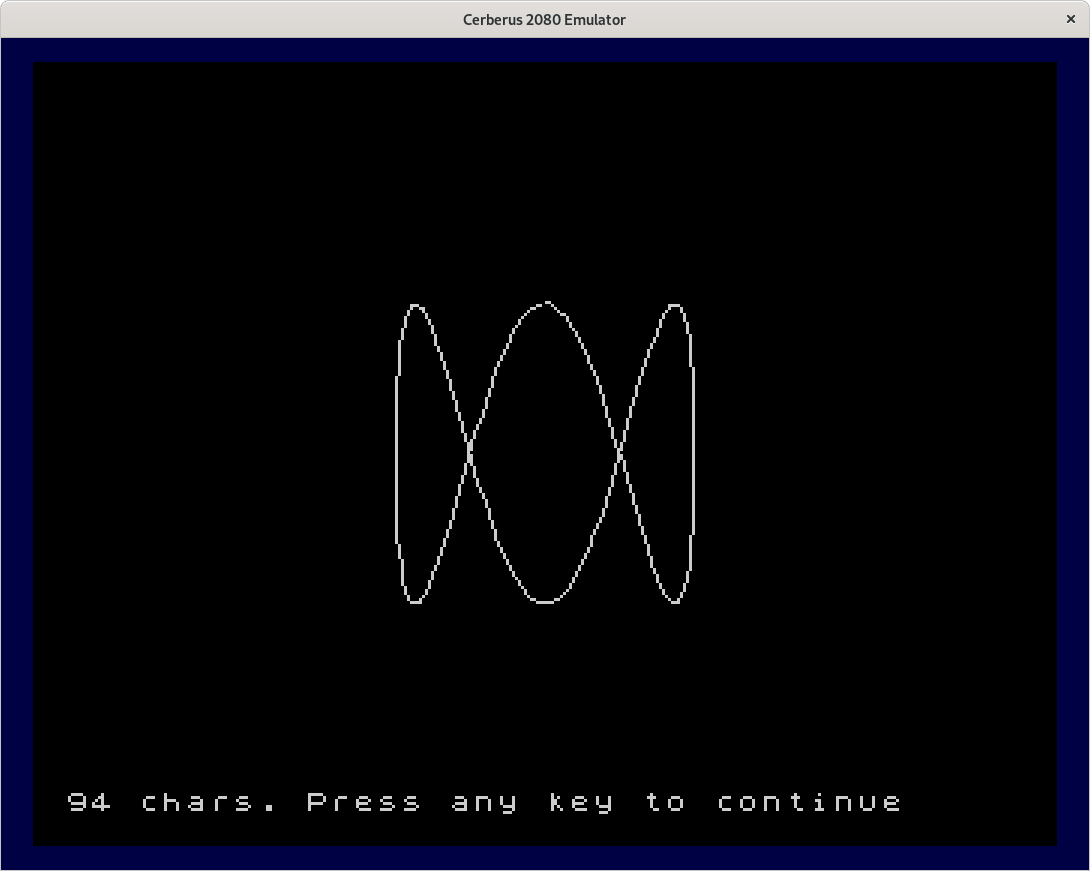
As we quickly use up characters when we draw lines, the program will be more useful if more characters are available for redefinition. Many old home computers had only capital letters and no lowercase, so we can sacrifice those. BBC Basic for SDL lets us redefine all printable characters, so we can use the lowercase characters as well. However, character codes 0..31 and 127 (delete) cannot be used. But as CERBERUS redefines them outside of BASIC, we can easily use them as well on Cerberus.
The third program allocates a byte array that contains all characters that can be redefined. This is the array chars% and ctop% is the index to the next free character. Whenever a character is allocated. ctop% is decremented. Furthermore, the third program has a more interesting line drawing pattern (consisting of 12 squares at different angles). It also adds a spiral figure and random triangles.
This is the third program graph03 in tokenized form and in ASCII. One other important addition: when the program is finished, it reloads the original character definitions. At the end of each screen it shows the number of free characters instead of the number of characters used. On CERBERUS we can use 197 characters: 0..31 and 91..255. All ASCII characters between space (32) and capital Z (90) remain available for display.
A fourth program adds three plot modes: set the pixel, clear the pixel or invert the pixel. Whenever a character cell is emptied, the character code is added to the free list and the character on the screen is replaced by a space. You can now draw lines and erase them indefinitely. All characters used when a line is drawn, will be freed when the line is erased. A demo is added to do just that. At the end the screen should show 197 free characters (on CERBERUS). The squares demo draws a few random lines after the figure is drawn. These lines are drawn in invert mode and when the line is drawn again, it disappears without a trace. Also any character codes are freed again. Regardless of the random lines, the screen should show 55 free characters in the end.
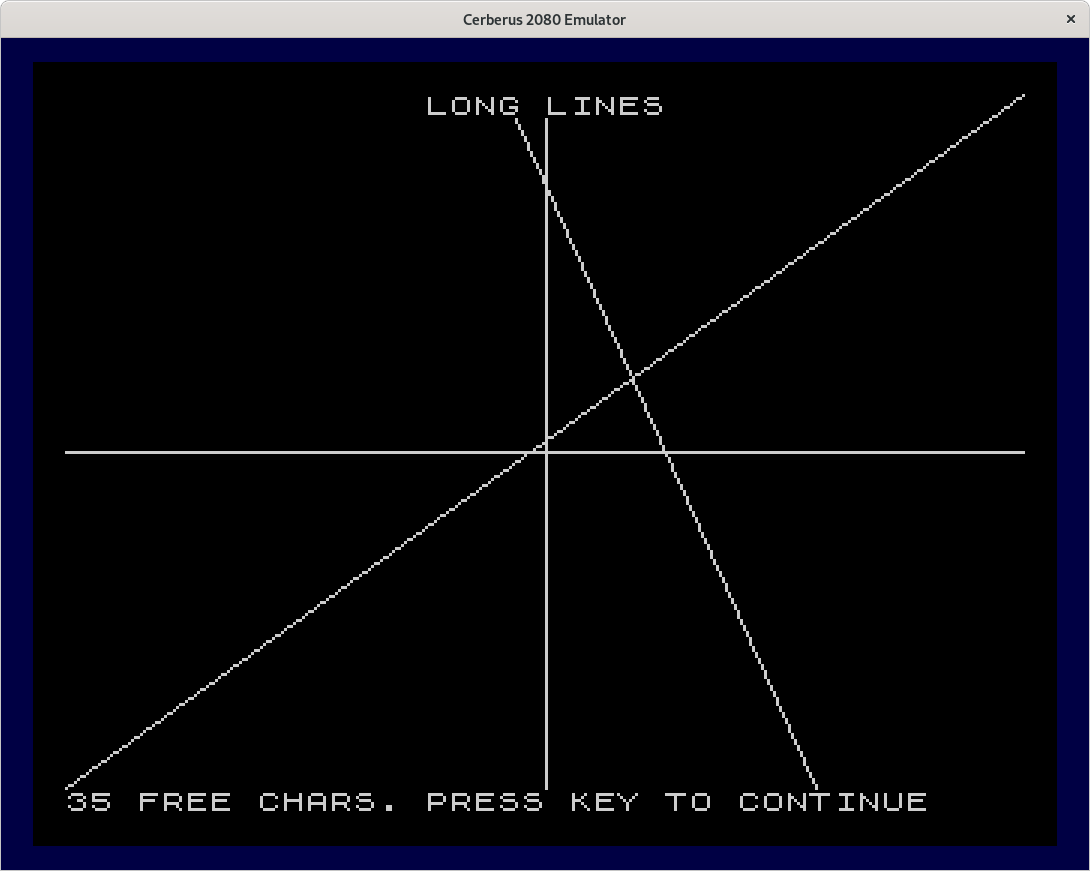
This is the fourth program graph04 in tokenized form and in ASCII. These are the long lines pattern and the 12 squares pattern.

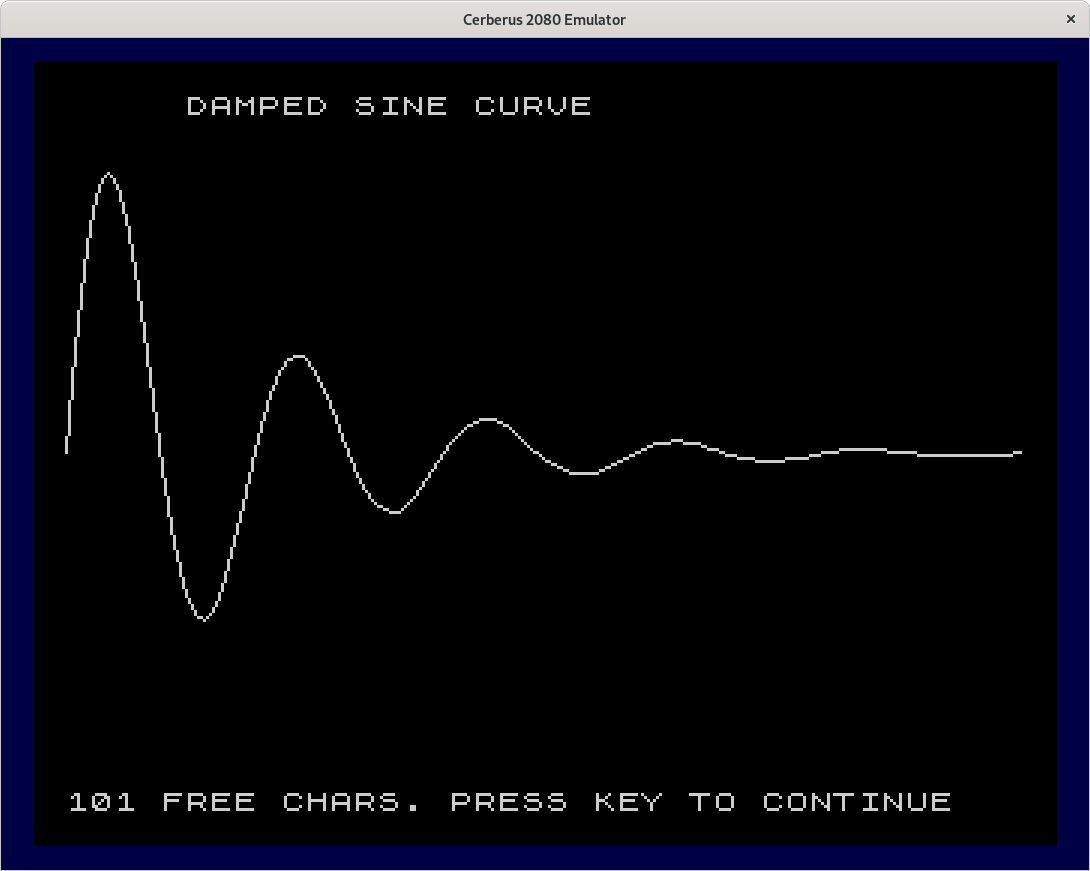
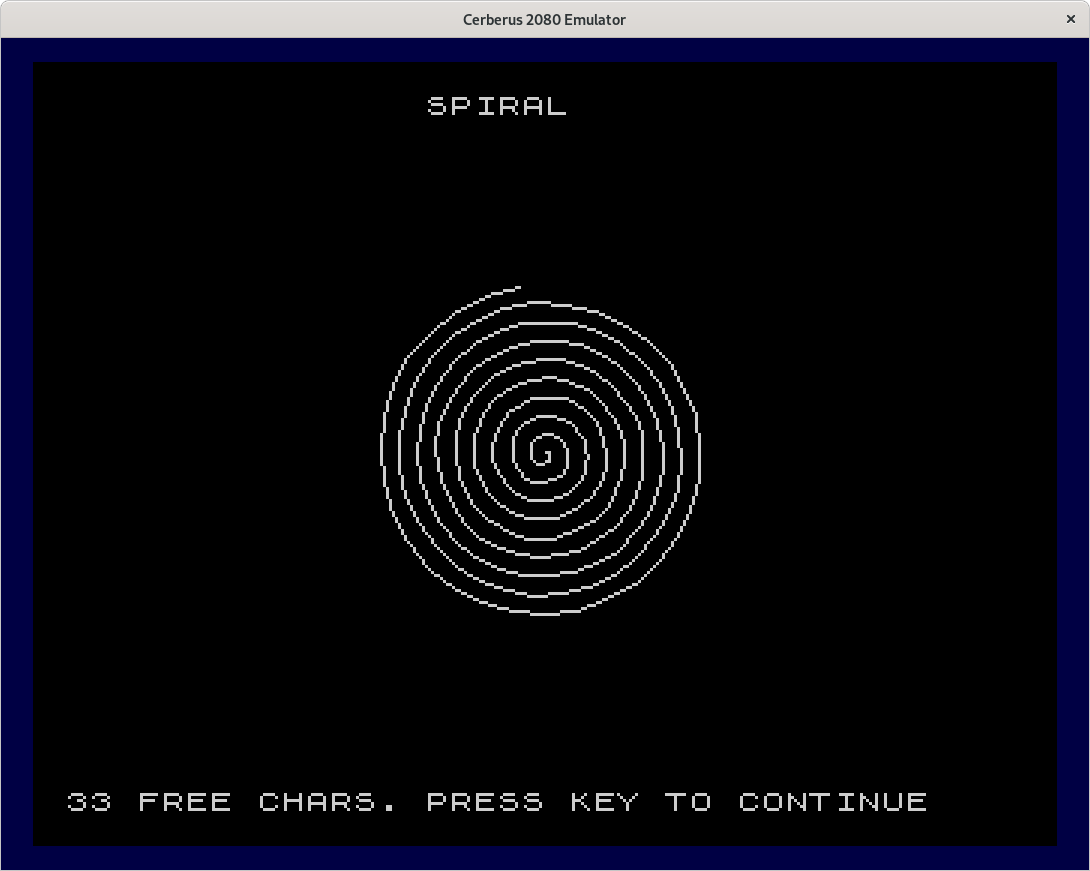
Also see the damped sine wave and the spiral.
When I wrote the fourth program with the pixel clear and invert modes, performance went from slow to sluggish. I still wanted to have this additional functionality, so I decided to speed it up using assembly language. All programs so far could still run on BBC Basic for SDL. They run much faster there, but we have fewer character codes to play with. As we would now use assembly language, I removed the compatibility code. I replaced the PROCplotdot procedure to a plotdot% assembly routine that could be called with parameters.
BBC Basic has a built-in assembler that has some peculiarities. Fortunately there is a free online manual for this version of BBC Basic, that also discusses assembly language and the CALL statement. Note the following
The parameters are passed via a block pointed to by the IX register. It contains the number of parameters as the first byte and then for each parameter one byte to indicate its type and two bytes for its address. In this routine I do not check the number and types of the parameters. This is not good programming practices, but in those days, who cared? The parameter values themselves are checked, so we do not plot outside the screen memory. Reading from invalid addresses does not do any real harm on CERBERUS. There are no segmentation fault traps and there is no nasty memory mapped I/O that you can trigger when reading the wrong address (as it was on the Apple II).
This optimization did gain much speed. While graph04 took over 35 seconds to draw the first screen with the long lines, graph05 does it in under 5 seconds. As only the plotdot routine is implemented in assembly language and the drawline routine is still in Basic, line drawing is still considerably slower than on Basic versions with built-in line drawing primitives. On the plus side, you can see the lines being plotted on the screen.
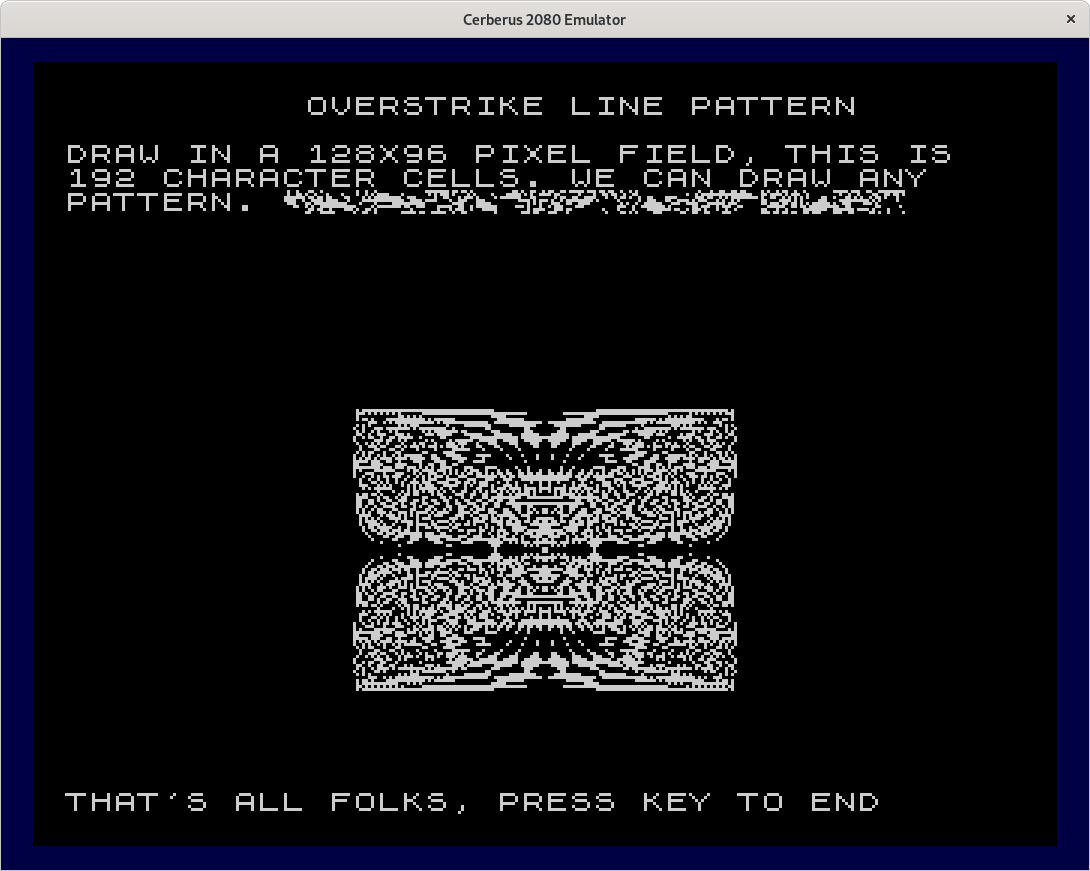
This is the fifth program graph05 in tokenized form and in ASCII. The final program contains a different Lissajous figure and it contains a scaled down version of the XOR-lines pattern. This pattern is drawn in a 128x96 pixel field that is completely covered by 192 character codes. Within this field we can draw arbitrary patterns. This is still better than the 80x60 pixels allowed by the block graphics of the standard character set. The program contains a surprise that will only be visible when you run the program for some time. This pattern will take over 80 minutes to draw.
The random triangles demo occasionally runs out of free characters and it fails to draw the last triangle. See how some portions of the lines are drawn and others are not. If a portion of the line happens to be in a character cell that was already allocated, it will be drawn, if it is in empty space, it will not be drawn.

Is there a way around this? Of course there is. We can share character codes on the screen that have the same bitmap. For example: the programs so far would allocate 40 distinct character codes when drawing a horizontal line across the width of the screen. But each of those 40 character cells would have the exact same bit pattern. We could define the bitmap for just one character code and use it 40 times. It is silly not to do this. But this is easier said than done if you want line drawing routines with normal parameters and lines can of course intersect each other.
This is the sixth program graph06 in tokenized form and in ASCII. As this program was used to prototype the algorithm, it was again written entirely in BASIC and it can run on BBC Basic for SDL. Hence it is based on graph04, not on graph05. Needless to say its speed is again slow. As it has to do more work than graph04, it is even slower than that, but not orders of magnitude slower. The first screen takes 45 seconds to draw, as opposed to 35 seconds for graph04. This indicates that the use of hash tables is effective. While I developed this program I had a version with linear search and no hash tables and this WAS an order of magnitude slower than that. The first screen now leaves 124 characters free, while it was only 35 in previous versions of the program.
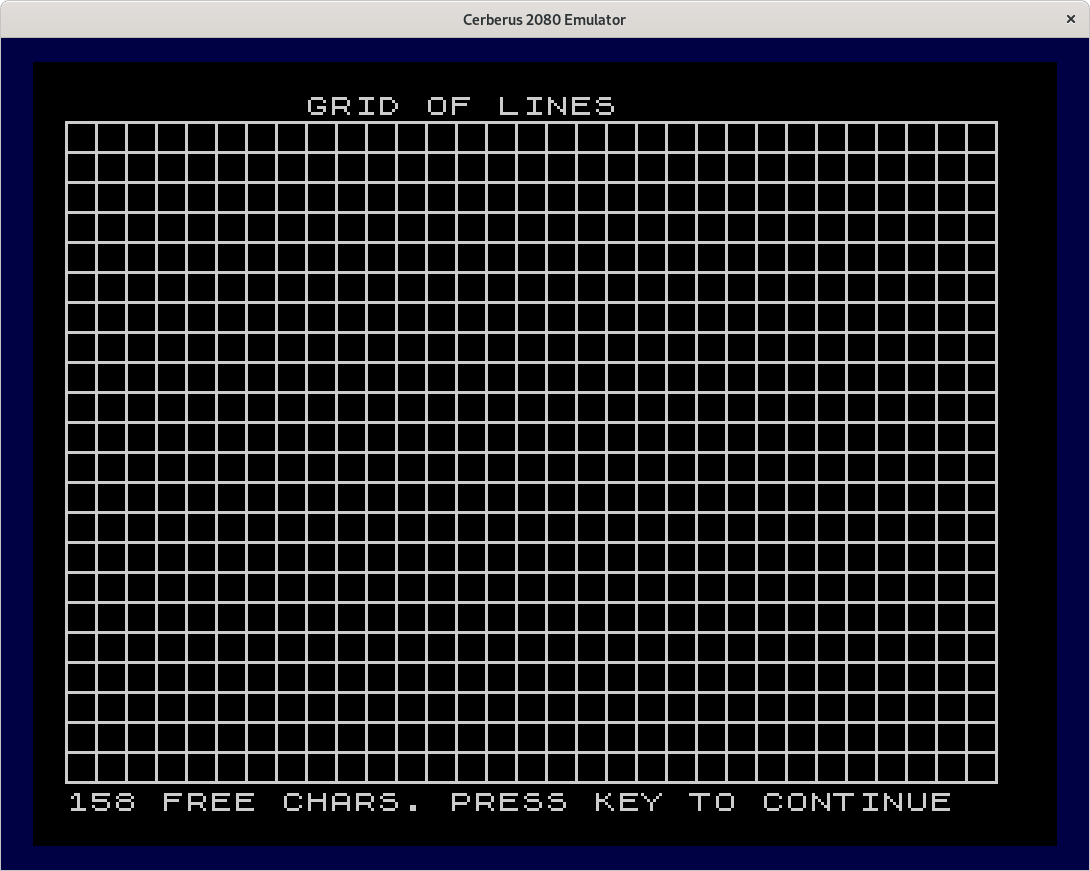
The line grid shown below has a the lines spaced 10 pixels apart, so it contains many different character bitmaps (38 in fact). But without sharing character codes, this will simply be unthinkable to draw. After drawing this grid, the program also draws and then erases random lines in invert mode, so the grid will be completely restored after erasing that line (not shown here). For figures involving curved lines the saving may not be big. Yet, the Lissajous figure shown below will be drawn completely with the new program while earlier programs would run out of characters.
How many character codes we really save is highly dependent on the figure we draw. On the left we see a pattern of 12 squares of side length 60. This one does benefit from shared character codes and it could not be drawn completely with earlier versions of the program. The figure on the right consists of 36 squares of side length 40. Despite its symmetry, it has no shared characters.


The variable lastchar% contains the character cell offset in video RAM where the last dot was plotted. It is either out of range for video RAM or it points to a cell containing a character that is redefinable and not shared with other character cells. This character is NOT contained within the hash table.
So if we plot a dot and the computed cell offset is identical to lastcell% we can just modify the character bitmap and be done with it. This is what we check at line 2500 of the PROCplotdot routine. So as long as we stay in the same character cell, we do not have to do any hash lookups and table manipulation.
So when the computed character cell offset is not the same as lastcell%, we first take care of the character stored in lastcell%. We can do one of three things:
After dealing with the character stored in lastchar%, we need to take care of the current character cell where we will plot a dot.
A hash function is a function that maps a value that consists of many bits (possibly variable, but in our case it is an 8-byte character bitmap) to a value that consist of a fixed number of bits (in this case an 8-bit byte). The hash function is fully deterministic, which means that each time we compute it for the same input, we get the same output and it should have an output that appears to be randomly distributed for different inputs. For example it is not desirable that all character bitmaps with a single byte 0xff and all other bytes 0 (horizontal line segments) map to the same hash value.
In graph06 we multiply each byte of the character bitmap with a different power of 3 and then add them together. We then take the sum modulo 257 and take the last significant byte of this (value 256 becomes 0). See FNHash% in line 3080. This should be a reasonably good hash function as it does modulo by a prime number and we can approximate modulo 257 by subtracting any carries that we get out of 8-bit addition when implementing this in assembler.
We have two 256-byte tables:
So again I set out to implement my algorithm in assembly language. This time I implemented PROCplotdot, PLOTclearscreen and PLOTdrawline all in assembler. When I had implemented just PLOTdot I had a speed comparable to that of graph05, when I also implemented PROCdrawline, the program really takes off. Lines are now shown instantaneously and you don't see them being plotted. The final demo runs almost ten times as fast as it was originally in graph05. There is nearly 1 kilobyte of machine code and 1280 bytes of tables.
The program contains all assembly code in one large chunk. This starts with the plotdot subroutine and it also contains clearscreen and drawline. It contains the subroutines hashchar, hashfind, addhash and remhash to support the hash table algorithm in plotdot. The code chunk contains most variables, but there are still separate DIM areas for chars%, refcnt% and hashtab% (hashtab% and hashlink are now combined in a single data area). The overall algorithm is almost the same as in graph06, but some details differ. The hash function is not the exact same function. It contains a multiplication by 3 and does all adds with carry, but each carry bit gets inverted before it is added. This gives it a similar effect as subtracting the carry and in turn this is similar to the modulo 257 function. Also the addhash subroutine adds the new entry to the start of the chain, rather than to the end, which is more efficient.
This is the seventh program graph07 in tokenized form and in ASCII. Enjoy it and run your own graphics programs on top of it.
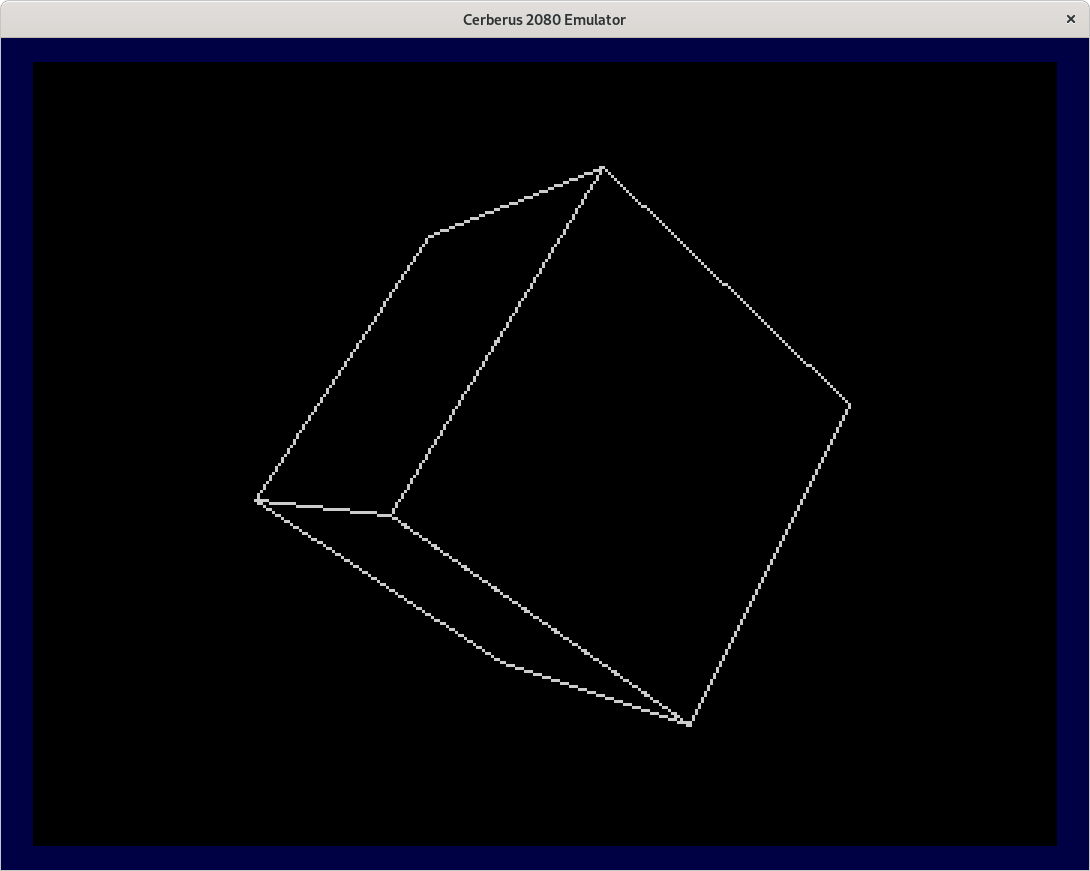
But instead of my demo program we can do the rotating cube demo with my line routines as well. This is the program hrcube in tokenized form and in ASCII.